





 |
ARI711S - ARTIFICIAL INTELLIGENCE - 1ST OPP - JUNE 2023 |
|
|
1 Page 1 |
▲back to top |

n Am I BI A u n IVER s ITY
OF SCIEnCE Ano TECHn OLOGY
Faculty of Computing and Informatics
Department of Computer Science
QUALIFICATION: Bachelor of Computer Science
QUALIFICATION CODE: 07BACS
COURSE: Artificial Intelligence
DATE: JUNE 2023
DURATION: 3 HOURS
LEVEL: 7
COURSE CODE: ARl711S
SESSION: 1
MARKS: 100
EXAMINER
MODERATOR:
FIRST OPPORTUNITY EXAMINATION QUESTION PAPER
MR STANTIN SIEBRITZ
MS PAULINA SHIFUGULA
THIS EXAM PAPER CONSISTS OF 7 PAGES
(Including this front page)
INSTRUCTIONS
1. This paper contains 5 questions.
2. Answer ALL questions on the examination booklet provided.
3. Marks/scores are indicated at the right end of each question.
4. Calculators are permitted.
5. NUSTexamination rules and regulations apply.
|
|
2 Page 2 |
▲back to top |

ARl7115 - FIRSTOPPORTUNITYEXAMINATIONJUNE 2023
QUESTION 1: SEARCH
[20]
State whether the following statements are either TRUEor FALSE.
1.1 Uniform-cost search will never expand more nodes than A*-search.
(2)
1.2 The heuristic h(n) = 0 is admissible for every search problem.
(2)
1.3 The heuristic h(n) = 1 is admissible for every search problem.
(2)
1.4 If h1(s) and h2(s) are two admissible A* heuristics, then their average
(2)
h3(s)= ½ h1(s)+ ½ h2(s)must also be admissible.
1.5 Depth-first search will always expand more nodes than breadth-first search.
(2)
1.6 Depth-first graph search is guaranteed to return an optimal solution.
(2)
1.7 Breadth-first graph search is guaranteed to return an optimal solution.
(2)
1.8 Uniform-cost graph search is guaranteed to return an optimal solution.
(2)
1.9 Greedy graph search is guaranteed to return an optimal solution.
(2)
1.10 A* graph search is guaranteed to return an optimal solution.
(2)
2
|
|
3 Page 3 |
▲back to top |
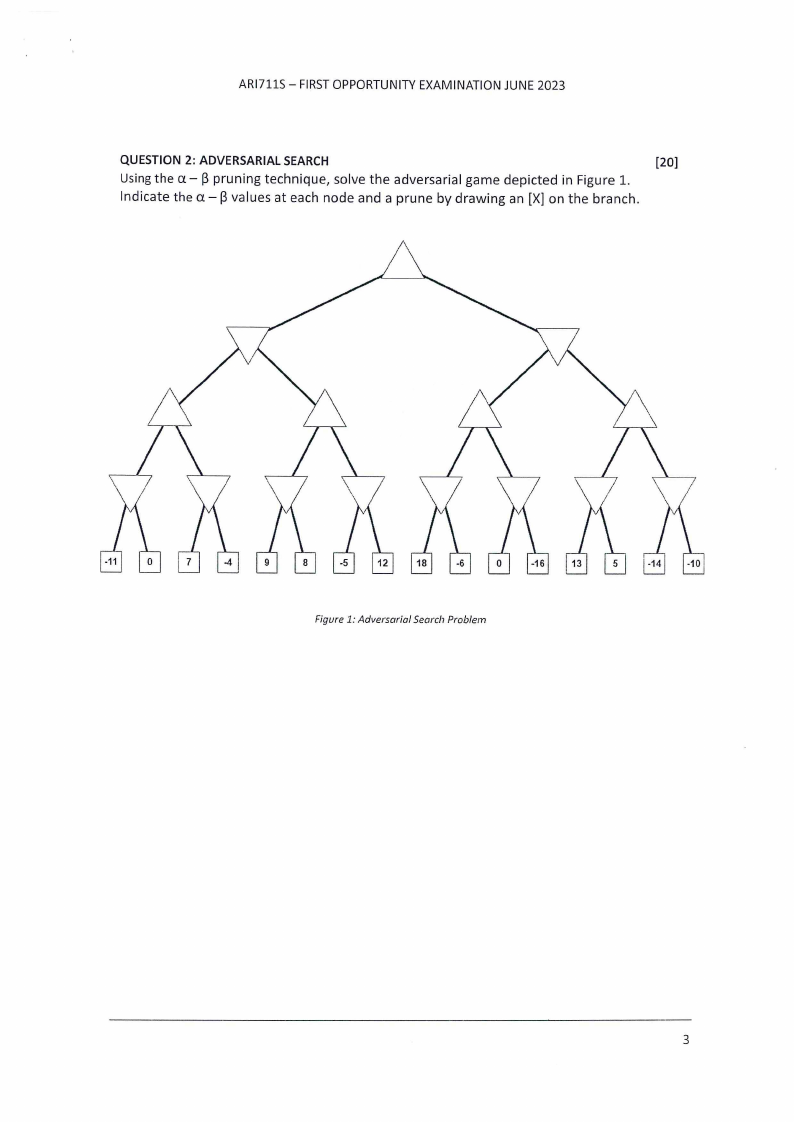
ARl711S - FIRSTOPPORTUNITYEXAMINATIONJUNE 2023
QUESTION 2: ADVERSARIALSEARCH
[20]
Usingthe a - pruning technique, solve the adversarial game depicted in Figure 1.
Indicate the a - values at each node and a prune by drawing an [X] on the branch.
Figure 1: Adversarial Search Problem
3
|
|
4 Page 4 |
▲back to top |

ARl711S - FIRSTOPPORTUNITYEXAMINATIONJUNE 2023
QUESTION 3: CSP
[20]
ARl711S Exams is coming up, and the ARl711S staff have yet to moderate the exam in order
to produce the memorandum. There are a total of 6 questions on the exam and each
question will cover a topic. Here is the format of the exam:
• Question 1: Search
• Question 2: Games (Adversarial Search)
• Question 3: CSPs
• Question 4: MDPs
• Question 5: True/False
• Question 6: Short Answer
There are 7 people on the course staff: Stantin, Luciano, Paulina, Judy, Kyle, Michael, and
Nick.
Each of them is responsible to work with Prof Jose Quenum on one question (but a
question could end up having more than one staff member, or potentially zero staff
assigned to it). However, the staff are pretty quirky and want the following constraints to
be satisfied:
(i) Luciano (L) will not work on a question together with Judy (J).
(ii) Kyle (K) must work on either Search, Games or CSPs
(iii) Michael (M) is very odd, so he can only contribute to an odd-numbered
question.
(iv) Nick (N) must work on a question that's before Michael (M)'s question.
(v) Kyle (K) must work on a question that's before Luciano (L)'s question
(vi) Stantin (S) does not like grading exams, so he must work on True/False.
(vii) Judy (J) must work on a question that's after Nick (N)'s question.
(viii) If Stantin (S) is to work with someone, it cannot be with Nick (N).
(ix) Nick (N) cannot work on question 6.
(x) Paulina (P) cannot work on questions 4, 5, or 6
(xi) Luciano (L) cannot work on question 5.
(xii) Luciano (L) must work on a question before Paulina (P)'s question.
3.1 Model this problem as a constraint satisfaction problem (CSP).Variables correspond (4)
to each of the staff members, J, P,N, L, M, S, K, and the domains are the questions
1, 2, 3, 4, 5, 6. After applying the unary constraints, what are the resulting domains
of each variable?
3.2 If we apply the Minimum Remaining Value (MRV) heuristic, which variable should
(2)
be assigned first?
3.3 Realizing this is a tree-structured CSP,we decide not to run backtracking search, and
instead use the efficient two-pass algorithm to solve tree-structured CSPs.We will
run this two-pass algorithm after applying the unary constraints from part 3.1.
Below is the linearized version of the tree-structured CSPgraph for you to work
with.
4
|
|
5 Page 5 |
▲back to top |

ARl711S - FIRSTOPPORTUNITY EXAMINATION JUNE 2023
I
I
2
2
2
2
2
2
2
3
:1
3
3
3
3
3
.]
ll
-1
,I
5
5
5
5
5
5
5
6
6
6
(j
6
6
(j
3.3.1 First Pass: Domain Pruning.
(7)
Passfrom right to left to perform Domain Pruning. Write the values that remain in
each domain for each variable.
3.3.2 Second Pass: Find Solution.
(7)
Passfrom left to right, assigning values for the solution. If there is more than one
possible assignment, choose the highest value.
5
|
|
6 Page 6 |
▲back to top |

ARl711S - FIRSTOPPORTUNITY EXAMINATION JUNE 2023
QUESTION 4: MDP
Consider the blocks world. The blocks can be on a table or in a box. Consider three generic
actions: ao, a1, and a2 described as follows:
ao: when applied to a block, will keep it in the box;
a1: when applied to a block, will move it on the table;
a2: when applied to two blocks, will move the first one on top of the second one.
[30]
Consider the following four states in the system:
Sa:all blocks are in the box, no block is on the table;
S1:only block B is on the table; all other blocks are in the box;
S2: both blocks Band Care on the table, with Con top of B;
S3: blocks B, C and Dare on the table, with Don top of C and Con top of B.
Furthermore, additional information is provided in Table 1, where each state has a reward,
possible actions and a transition model for each action. Note that for a given action, the
probability values indicated in its transition model all sum up to 1.
State
So
Reward
10
S1
20
S2
30
S3
100
Action
aob
a1b
aoc
a1c
a2c
aod
a1d
a2d
Transition
(1, So)
(0.25 , So); (0.75 , S1)
(1, S1)
(0.5 , Si) ; (0.25 , S4); (0.25 , S2)
(0.6 I S1); (0.4, S2)
(1, S2)
(0.5, S2); (0.25, Ss); (0.25, S3)
(0.6 I S2); (0.4, S3)
Table 1: Additional Information
Assuming we model this problem as Markov Decision Process (MDP) and consider a
discount value Y = 0.4
4.1 Provide the Bellman equation variations for policy extraction.
(5)
4.2 Extract the policy of each of the states So,S1and S2at k=2 (third iteration) using the (20)
policy extraction algorithm. Note that although the states S4and Sshave not been
defined, they should be assumed in the system with a reward of 40 each.
4.3 Consider the following policy, no ={So aob, S1 a1c, S2 a2d}. Is no optimal?
(5)
Explain.
6
|
|
7 Page 7 |
▲back to top |

ARl711S - FIRSTOPPORTUNITYEXAMINATIONJUNE 2023
QUESTION 5: REINFORCEMENT LEARNING
(10]
Recall that reinforcement learning agents gather tuples of the form
< St; Gt; rt+1; St+1; Gt+1 > to update the value or Q-value function. In both of the following
cases, the agent acts at each step as follows: with probability 0.5 it follows a fixed (not
necessarily optimal) policy rc and otherwise it chooses an action uniformly at random.
Assume that in both cases updates are applied infinitely often, state-action pairs are all
visited infinitely often, the discount factor satisfies O < Y < 1, and learning rates are all
decreased at an appropriate pace.
5.1 The Q-learning agent performs the following update:
(5)
Will this process converge to the optimal Q-value function? If yes, write "Yes". If not,
give an interpretation (in terms of kind of value, optimality, etc.) of what it will
converge to, or state that it will not converge.
5.2 Another reinforcement learning algorithm is called SARSA,and it performs the
(5)
update:
Q(s1.,at;)~ Q(s1.,a.1;+) afrt.+1 + ~iQ(st+l: O.t+1)- Q(st, a1,)]
Will this process converge to the optimal Q-value function? If yes, write "Yes". If not,
give an interpretation (in terms of kind of value, optimality, etc.) of what it will
converge to, or state that it will not converge.
END OF EXAMINATION PAPER
7