





 |
ARI711S - ARTIFICIAL INTELLIGENCE - 2ND OPP - JULY 2023 |
|
|
1 Page 1 |
▲back to top |

nAm I BIA un IVE RSITY
OF SCIEnCE Ano TECHn OLOGY
Faculty of Computing and Informatics
Department of Computer Science
QUALIFICATION: Bachelor of Computer Science
QUALIFICATION CODE: 07BACS
COURSE: Artificial Intelligence
DATE: JULY2023
DURATION: 3 HOURS
LEVEL: 7
COURSE CODE: ARl711S
SESSION: 2
MARKS: 100
SUPPLEMENTARY/ SECOND OPPORTUNITY EXAMINATION QUESTION PAPER
EXAMINER
MR STANTIN SIEBRITZ
MODERATOR:
MS PAULINA SHIFUGULA
THIS EXAM PAPER CONSISTS OF 8 PAGES
{Including this front page)
INSTRUCTIONS
1. This paper contains 6 questions.
2. Answer ALL questions on the examination booklet provided.
3. Marks/scores are indicated at the right end of each question.
4. Calculators are permitted.
5. NUST examination rules and regulations apply.
|
|
2 Page 2 |
▲back to top |

ARl711S - SECONDOPPORTUNITYEXAMINATIONJULY2023
QUESTION 1: SHORT ANSWERS
[20]
State whether the following statements are either TRUEor FALSE.
1.1 Uniform-cost search will never expand more nodes than A*-search.
(2)
1.2 Depth-first search will always expand more nodes than breadth-first search.
(2)
1.3 The most-constrained variable heuristic provides a way to select the next variable to (2)
assign in a backtracking search for solving a CSP.
1.4 By using the most-constrained variable heuristic and the least-constraining value
(2)
heuristic we can solve every CSPin time linear in the number of variables.
1.5 When using alpha-beta pruning, it is possible to get an incorrect value at the root
(2)
node by choosing a bad ordering when expanding children.
1.6 When using alpha-beta pruning, the computational savings are independent of the (2)
order in which children are expanded.
1.7 For an MDP (S; A; T; Y; R) if we only change the reward function Rthe optimal policy (2)
is guaranteed to remain the same.
1.8 Policies found by value iteration are superior to policies found by policy iteration.
(2)
1.9 Q-learning can learn the optimal Q-function Q* without ever executing the optimal (2)
policy.
1.10 If an MDP has a transition model T that assigns non-zero probability for all T(s; a; s0) (2)
then Q-learning will fail.
2
|
|
3 Page 3 |
▲back to top |

ARl711S - SECONDOPPORTUNITYEXAMINATIONJULY2023
QUESTION 2: SEARCH
[20)
For each of the following graph search strategies, work out the order in which states are
expanded, as well as the path returned by graph search. In all cases, assume ties resolve in
such a way that states with earlier alphabetical order are expanded first. The start and goal
state are Sand G, respectively.
2.1 Depth-First Search
(4)
2.2 Breadth-First Search
(4)
2.3 Uniform Cost Search
(4)
2.4 Greedy search with the heuristic h shown on the graph.
(4)
2.5 A* search with the same heuristic.
(4)
3
|
|
4 Page 4 |
▲back to top |

ARl711S - SECONDOPPORTUNITYEXAMINATION JULY2023
QUESTION 3: CSP
[6]
You are in charge of scheduling for computer science classes that meet Mondays,
Wednesdays and Fridays. There are 5 classes that meet on these days and 3 professors who
will be teaching these classes. You are constrained by the fact that each professor can only
teach one class at a time.
The classes are:
• Class 1- Intro to Programming: meets from 8:00-9:00am
• Class 2 - Intro to Artificial Intelligence: meets from 8:30-9:30am
• Class 3 - Natural Language Processing: meets from 9:00-10:00am
• Class4 - Computer Vision: meets from 9:00-10:00am
• Class 5 - Machine Learning: meets from 10:30-11:30am
The professors are:
• Professor A, who is qualified to teach Classes 1, 2, and 5.
• Professor B, who is qualified to teach Classes 3, 4, and 5.
• Professor C, who is qualified to teach Classes 1, 3, and 4.
3.1 Formulate this problem as a CSPproblem in which there is one variable per class,
(2)
stating the domains, and constraints. Constraints should be specified formally and
precisely, but may be implicit rather than explicit.
3.2 Draw the constraint graph associated with your CSP.
(2)
3.3 Provide a possible solution to the CSPscheduling problem. All variables should be
(2)
assigned and no constraints broken.
4
|
|
5 Page 5 |
▲back to top |

ARl711S - SECONDOPPORTUNITYEXAMINATIONJULY2023
QUESTION 4: CSP
[14]
After years of struggling through mazes, Pacman has finally made peace with the ghosts,
Blinky, Pinky, Inky, and Clyde, and invited them to live with him and Ms. Pacman. The move
has forced Pacman to change the rooming assignments in his house, which has 6 rooms.
He has decided to figure out the new assignments with a CSPin which the variables are
Pacman (P), Ms. Pacman (M), Blinky (B), Pinky (K),Inky (I), and Clyde (C), the values are
which room they will stay in, from 1-6, and the constraints are:
i) No two agents can stay in the same room vi) Bis even
ii) P > 3
vii) I is not 1 or 6
iii) K is less than P
viii) (1-C)= 1
iv) M is either 5 or 6
ix) (P-B) = 2
v) P> M
4.1 Unary constraints: On the grid below cross out the values from each domain that are (4)
eliminated by enforcing unary constraints.
p 1 2 :3 4 5 6
B 1234 56
C 123456
K 123456
I 1 2 :3 4 5 6
M123456
4.2 MRV:According to the Minimum Remaining Value (MRV) heuristic, which variable
(2)
should be assigned to first?
4.3 Forward Checking: For the purposes of decoupling this problem from your solution
(4)
to the previous problem, assume we choose to assign P first, and assign it the value
6. What are the resulting domains after enforcing unary constraints (from part 4.1)
and running forward checking for this assignment?
p
6
B 123456
C 123456
K 1234 56
I 1 2 :3 4 5 6
M12 3 4 56
4.4 Iterative Improvement: Instead of running backtracking search, you decide to start (4)
over and run iterative improvement with the min-conflicts heuristic for value
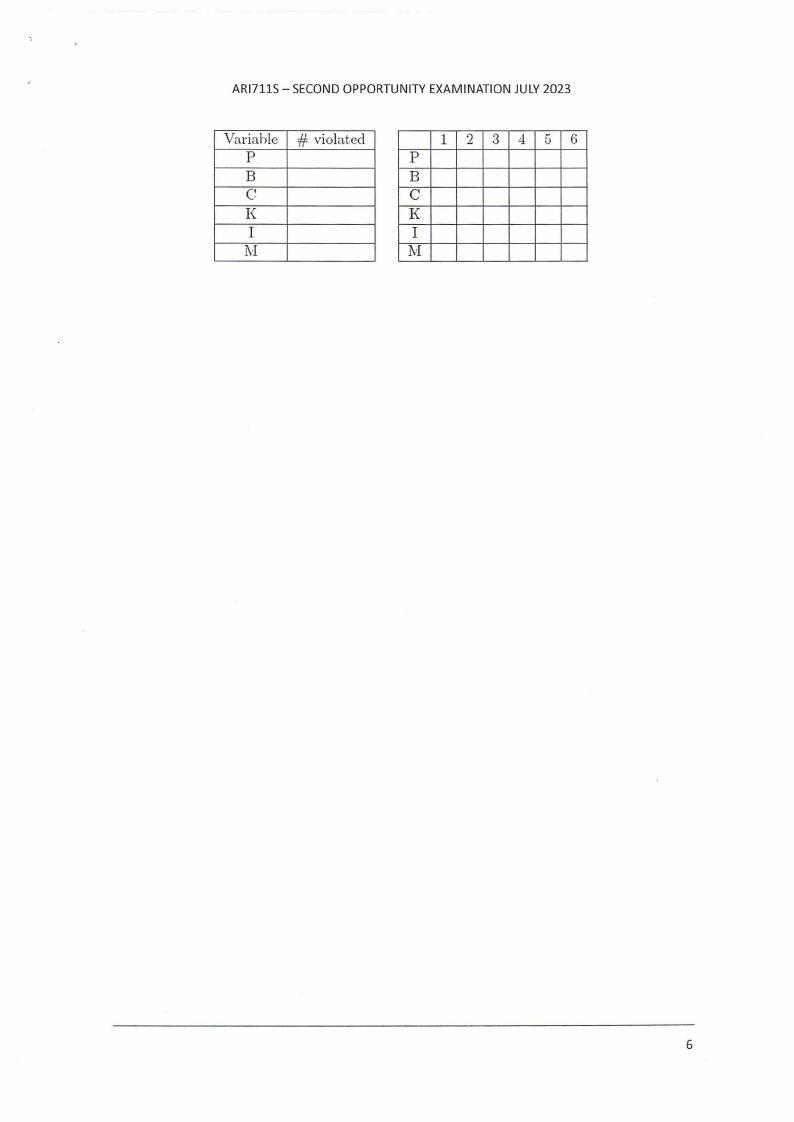
selection. Starting with the following assignment: P:6, B:4, C:3, K:2, 1:1,M:5
First, for each variable write down how many constraints it violates in the table
below. Then, in the table on the right, for all variables that could be selected for
assignment, put an [X] in any box that corresponds to a possible value that could be
assigned to that variable according to min-conflicts. When marking next values a
variable could take on, only mark values different from the current one.
5
|
|
6 Page 6 |
▲back to top |
ARl711S- SECOND OPPORTUNITY EXAMINATION JULY 2023
Variable
p
B
C
K
I
M
# violated
1 2 :3 4 5 ('i
p
B
C
K
I
l'vI
6
|
|
7 Page 7 |
▲back to top |

ARl711S - SECONDOPPORTUNITYEXAMINATION JULY2023
QUESTION 5: MDP
[20)
The following problems take place in various scenarios of the gridworld MDP (as in
Assignment P3). In all cases, A is the start state and double-rectangle states are exit states.
From an exit state, the only action available is Exit, which results in the listed reward and
ends the game (by moving into a terminal state X, not shown).
From non-exit states, the agent can choose either Left or Right actions, which move the
agent in the corresponding direction. There are no living rewards; the only non-zero
rewards come from exiting the grid.
Throughout this problem, assume that value iteration begins with initial values V0(s) = 0 for
all states s.
First, consider the following mini-grid. For now, the discount is Y = 1 and legal movement
actions will always succeed (and so the state transition function is deterministic).
IEJI
5.1 What is the optimal value V*(A)?
(1)
5.2 When running value iteration, remember that we start with Vo(s)= 0 for alls. What (2)
is the first iteration k for which Vk(A)will be non-zero?
5.3 What will Vk(A)be when it is first non-zero?
( 1)
5.4 After how many iterations k will we have Vk(A)= V*(A)? If they will never become
(2)
equal, write never.
Now the situation is as before, but the discount is less than 1.
5.5 If Y = 0.5, what is the optimal value V*(A)?
(3)
5.6 For what range of values Yof the discount will it be optimal to go Right from A?
(4)
Remember that 0 :5 Y:5 1. Write all or none if all or no legal values of have this
property.
Let's kick it up a notch! The Left and Right movement actions are now stochastic and fail with
probability f. When an action fails, the agent moves up or down with probability f/2 each. When
there is no square to move up or down into (as in the one-dimensional case), the agent stays in
place. The Exit action does not fail.
For the following mini-grid, the failure probability is f = 0.5 and the discount is Y = 1
A IEJI
5.7 What is the optimal value V*(A)?
(1)
5.8 When running value iteration, what is the smallest value of k for which Vk(A)will (1)
be non-zero?
5.9 What will Vk(A)be when it is first non-zero?
(2)
5.10 After how many iterations k will we have Vk(A)= V*(A)? If they will never become (3)
equal, write never. Motivate your answer.
7
|
|
8 Page 8 |
▲back to top |

ARl711S - SECONDOPPORTUNITYEXAMINATIONJULY2023
QUESTION 6: REINFORCEMENT LEARNING
[10]
Assume we have an MOP with state space 5, action space A, reward function R(s; a; s'), and
discount Y.
Our eventual goal is to learn a policy that can be used by a robot in the real world.
However, we only have access to simulation software, not the robot directly. We know that
the simulation software is built using the transition model T5;m(s;a; s') which is
unfortunately different than the transition model that governs our real robot, T,eai(s;a; s').
Without changing the simulation software, we want to use the samples drawn from the
simulator to learn Q-values for our real robot.
Recall the Q-learning update rule. Given a sample (s; a; s'; r}, it performs the following
update:
6.1 Assuming the samples are drawn from the simulator, which new update rule will
(6)
learn the correct Q-value functions for the real-world robot? Provide the correct
update rule and explain.
6.2 Now consider the case where we haven real robots with transition models
(4)
T1,eai(s;a; s'}, ... , T",eai(sa; ;s') and still only one simulator. Is there a way to learn
policies for all n robots simultaneously by using the same samples from the
simulator? If yes, explain how. If no, explain why not. (1-2 sentences)
END OF EXAMINATION PAPER
8